
rpcx在学而思公司得到了广泛的应用,看看他们在使用rpcx和zookeeper的过程中发现的服务无法发现的问题。
线上环境微服务发现为什么更新不了?本文通过tcpdump分析微服务与zookeeper的数据交互;结合代码review,寻找服务发现框架可能出现的异常。需要特别注意zookeeper监听是一次性的;而Golang并发问题也很容易被忽视。
问题引入
2020-12-25日晚,突然接收到少量错误日志报警『failed to dial server: dial tcp xxxx:yy: i/o timeout』。原来是微服务客户端请求服务端,连接失败。
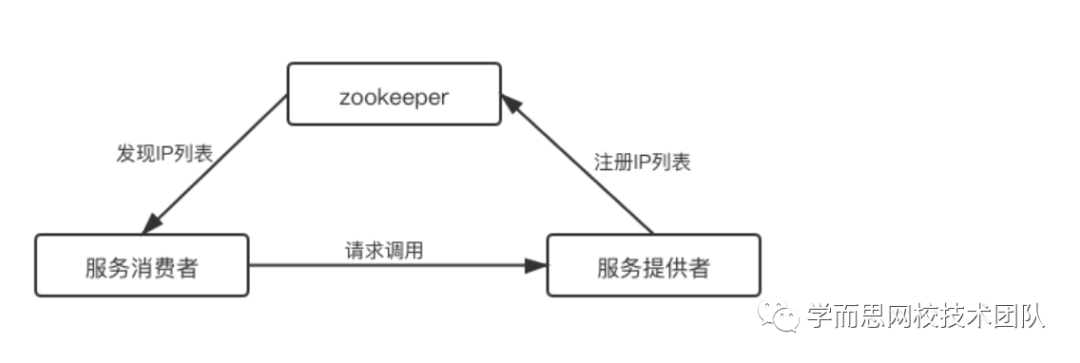
简单介绍下服务现状:我们的服务部署在k8s环境,微服务框架我们使用的是smallnest/rpcx,注册中心基于zookeeper,链路如下图所示:
- 第一步:这些连接超时的pod是有什么异常吗?根据连接超时的服务端IP地址查找对应的pod,发现没有一个pod是这个IP地址;那这个IP地址是从哪来的呢?难道是在某个隐秘的角落启动的?
- 第二步:连接注册中心,查看该服务注册的IP列表,发现也不存在上面超时的IP地址。
- 进一步:这个异常IP地址,k8s环境历史确实分配过;猜测服务端重启后,IP地址变了,但是客户端却没有更新IP列表,导致还请求老的IP地址。
另外,错误日志只集中在一个客户端,即只有一个客户端没有更新服务端的IP列表。初步猜测可能有两种原因:
- 1)这个客户端与zookeeper之间连接存在异常,所以zookeeper无法通知数据变更;
- 2)服务发现框架存在代码异常,且只在某些场景触发,导致无法更新本地IP列表,或者是没有watch数据变更。
针对第一种猜测,很简单登录到该异常客户端,查看与zookeeper之间的连接即可:
1
2
3
4
|
# netstat -anp | grep 2181
tcp 0 0 xxxx:51970 yyyy:2181 ESTABLISHED 9/xxxx
tcp 0 0 xxxx:40510 yyyy:2181 ESTABLISHED 9/xxx
|
可以看到存在两条正常的TCP连接,为什么是两条呢?因为该进程不止作为客户端访问其他服务,还作为服务端供其他客户端调用,其中一条连接是用来注册服务,另外一条连接用来发现服务。tcpdump抓包看看这两条连接的数据交互:
1
2
3
4
5
|
23:01:58.363413 IP xxxx.51970 > yyyy.2181: Flag [P.], seq 2951753839:2951753851, ack 453590484, win 356, length 12
23:01:58.363780 IP yyyy.2181 > xxxx.51970: Flags [P.], seq 453590484:453590504, ack 2951753851, win 57, length 20
23:01:58.363814 IP xxxx.51970 > yyyy.2181: Flags [.], ack 453590504, win 356, length 0
……
|
上面省略了抓包的内容部分。注意zookeeper点采用二进制协议,不太方便识别但是基本可以确信,这是ping-pong心跳包(定时交互,且每次数据一致)。并且,两条连接都有正常的心跳包频繁交互。
pod与zookeeper之间连接正常,那么很可能就是服务发现框架的代码问题了。
模拟验证
通过上面的分析,可能的原因是:服务发现框架存在代码异常,且只在某些场景触发,导致无法更新本地IP列表,或者是没有watch数据变更。
客户端有没有watch数据变更,这一点非常容易验证;只需要重启一台服务,客户端tcpdump抓包就行。只不过zookeeper点采用二进制协议,不好分析数据包内容。
简单介绍下zookeeper通信协议;如下图所示,图中4B表示该字段长度为4Byte。
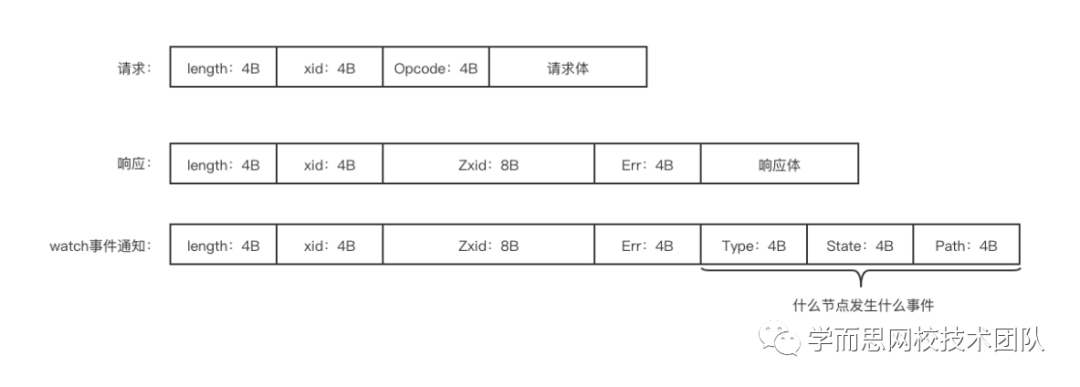
可以看到,每一个请求(响应),头部都有4字节标识该请求体的长度;另外,请求头部Opcode标识该请求类型,比如获取节点数据,创建节点等。watch事件通知是没有请求,只有响应,其中Type标识事件类型,Path为发生事件的节点路径。
从zookeeper SDK可以找到所有请求类型,以及事件类型的定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
const (
opNotify = 0
opCreate = 1
opDelete = 2
opExists = 3
opGetData = 4 //获取节点数据,这是我们需要关注的
opSetData = 5
opGetAcl = 6
opSetAcl = 7
opGetChildren = 8
opSync = 9
opPing = 11
opGetChildren2 = 12 //获取子节点列表,这是我们需要关注的
opCheck = 13
opMulti = 14
opClose = -11
opSetAuth = 100
opSetWatches = 101
)
const (
EventNodeCreated EventType = 1
EventNodeDeleted EventType = 2
EventNodeDataChanged EventType = 3
EventNodeChildrenChanged EventType = 4 //子节点列表变化,这是我们需要关注的
)
|
下面可以开始操作了,客户端tcpdump开启抓包,服务端杀死一个pod,分析抓包数据如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
//zookeeper数据变更事件通知
23:02:02.717505 IP xxxx.2181 > xxxx.51970: Flags [P.], seq 453590524:453590585, ack 2951753863, win 57, length 61
0000 0039 ffff ffff ffff ffff ffff .....9..........
0x0050: ffff 0000 0000 0000 0004 0000 0003 0000 ................
0x0060: 001d xxxx xxxx xxxx xxxx xxxx xxxx xxxx ../xxxxxxxxxxxxx
0x0070: xxxx xxxx xxxx xxxx xxxx xxxx xxxx xx xxxxxxxxxxxxxxx
23:02:02.717540 IP xxxx.51970 > xxxx.2181: Flags [.], ack 453590585, win 356, length 0
//客户端发起请求,获取子节点列表
23:02:02.717752 IP xxxx.51970 > xxxx.2181: Flags [P.], seq 2951753863:2951753909, ack 453590585, win 356, length 46
0000 002a 0000 4b2f 0000 000c 0000 .....*..K/......
0x0050: 001d xxxx xxxx xxxx xxxx xxxx xxxx xxxx ../xxxxxxxxxxxxx
0x0060: xxxx xxxx xxxx xxxx xxxx xxxx xxxx xx00 xxxxxxxxxxxxxxx.
//zookeeper响应,包含服务端所有节点(IP)
23:02:02.718500 IP xxxx.2181 > xxxx.51970: Flags [P.], seq 453590585:453591858, ack 2951753909, win 57, length 1273
//遍历所有节点(IP),获取数据(metadata)
23:02:02.718654 IP xxxx.51970 > xxxx.2181: Flags [P.], seq 2951753909:2951753978, ack 453591858, win 356, length 69
0000 0041 0000 4b30 0000 0004 0000 .....A..K0......
0x0050: 0034 xxxx xxxx xxxx xxxx xxxx xxxx xxxx .4/xxxxxxxxxxxxx
0x0060: xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxxxxxxxxxxxxxx
0x0070: xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxxxxxxxxxxxxxx
0x0080: xxxx xxxx xxxx 00 xxxxxxx
23:02:02.720273 IP xxxx.2181 > xxxx.51970: Flags [P.], seq 453591858:453591967, ack 2951753978, win 57, length 109
0000 0069 0000 4b30 0000 0003 0ab3 .....i..K0......
0x0050: ad90 0000 0000 0000 0011 6772 6f75 703d ..........group=
0x0060: 6f6e 6c69 6e65 2674 7073 3d00 0000 030a online&tps=.....
0x0070: b2ff ed00 0000 030a b3ad 5800 0001 76ae ..........X...v.
0x0080: d003 dd00 0001 76af 051d 6d00 0000 3a00 ......v...m...:.
0x0090: 0000 0000 0000 0001 703f 90a3 f679 ce00 ........p?...y..
0x00a0: 0000 1100 0000 0000 0000 030a b2ff ed ...............
……
|
整个过程的交互流程如下图所示:

可以看到,zookeeper在数据变更时通知客户端了,而客户端也拉取最新节点列表了,而且获取到的节点IP列表都是正确的。这就奇怪了,都已经获取到最新的IP列表了,为什么还请求老的IP地址?是没有更新内存中的数据吗?这就需要review代码了。
代码Review
我们的微服务框架使用的是rpcx,监听zookeeper数据变更的逻辑,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
for {
_, _, eventCh, err := s.client.ChildrenW(s.normalize(directory))
select {
case e := <-eventCh:
if e.Type == zk.EventNodeChildrenChanged {
keys, stat, err := s.client.Children(s.normalize(directory))
for _, key := range keys {
pair, err := s.Get(strings.TrimSuffix(directory, "/") + s.normalize(key))
}
}
}
}
|
注意获取子节点列表的两个方法,ChildrenW以及Children;这两是有区别的:
1
2
3
4
5
6
7
8
9
10
|
func (c *Conn) Children(path string) ([]string, *Stat, error) {
_, err := c.request(opGetChildren2, &getChildren2Request{Path: path, Watch: false}, res, nil)
return res.Children, &res.Stat, err
}
func (c *Conn) ChildrenW(path string) ([]string, *Stat, <-chan Event, error) {
_, err := c.request(opGetChildren2, &getChildren2Request{Path: path, Watch: true}, res, func(req *request, res *responseHeader, err error) {
return res.Children, &res.Stat, ech, err
}
|
原来,方法的后缀『W』代表着是否设置监听器。这里读者需要知道,zookeeper的监听器是一次性的。即客户端设置监听器后,数据变更时候,zookeeper查询监听器通知客户端,同时会删除该监听器。这就导致下次数据变更时候不会通知客户端了。
这有什么问题吗?也许会有问题。客户端接收到数据变更后主要有三步逻辑:
- 1)获取子节点列表,注意这时候并没有设置监听器;
- 2)遍历所有节点获取数据;
- 3)获取子节点列表,设置监听器,等待zookeeper事件通知。
注意从第一步到第三步,是有耗时的,特别是服务端节点数目过多时候,多次请求耗时必然更高,那么在这之间的数据变更客户端是感知不到的。再结合代码升级流程,是滚动升级,即启动若干新版本pod(目前配置25%数目),如果这些pod正常启动,则杀掉部分老版本pod;以此类推。
如果从第一部分新版本pod启动,到最后一部分新版本pod启动以及杀掉最后一些老版本pod,之间间隔非常短呢?小于上面第一步到第三步耗时呢?这样就会导致,客户端既存在老的IP列表,也存在新的IP列表。(上一小节模拟验证时候,只是杀死一个pod验证数据监听机制,并没有模拟大量pod重启过程并分析数据交互,因此无法确定这类场景是否存在问题)。整个过程如下图所示:

继续分析日志,发现客户端请求所有服务端的IP地址都是错误的,即客户端并不存在新的IP地址,不符合该场景。另外,再回首分析下模拟验证时候抓的数据包,第一步到第三步的时间间隔是非常非常小的,毕竟服务端机器数目不多,内网访问zookeeper也比较快,而滚动发布过程一般很慢,远大于该间隔。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
//第一步获取子节点列表,没有设置监听器;注意最后一个字节为0x00,即watch=false
23:02:02.717752 IP xxxx.51970 > xxxx.2181: Flags [P.], seq 2951753863:2951753909, ack 453590585, win 356, length 46
0000 002a 0000 4b2f 0000 000c 0000 .....*..K/......
0x0050: 001d xxxx xxxx xxxx xxxx xxxx xxxx xxxx ../xxxxxxxxxxxxx
0x0060: xxxx xxxx xxxx xxxx xxxx xxxx xxxx xx00 xxxxxxxxxxxxxxx.
//第一步获取子节点列表,并设置监听器;注意最后一个字节为0x01,即watch=true
23:02:02.768422 IP xxxx.51970 > xxxx.2181: Flags [P.], seq 2951757025:2951757071, ack 453596850, win 356, length 46
0000 002a 0000 4b5d 0000 000c 0000 .....*..K]......
0x0050: 001d xxxx xxxx xxxx xxxx xxxx xxxx xxxx ../xxxxxxxxxxxxx
0x0060: xxxx xxxx xxxx xxxx xxxx xxxx xxxx xx01 xxxxxxxxxxxxxxx.
//间隔50ms左右
|
不过,zookeeper监听器一次性机制还是需要关注,以防出现数据变更无法同步问题。
柳暗花明
还能有什么原因呢?只能继续扒代码了,既然rpcx获取到了最新的IP列表,为什么没有更新呢?这就需要重点分析rpcx数据更新逻辑了。

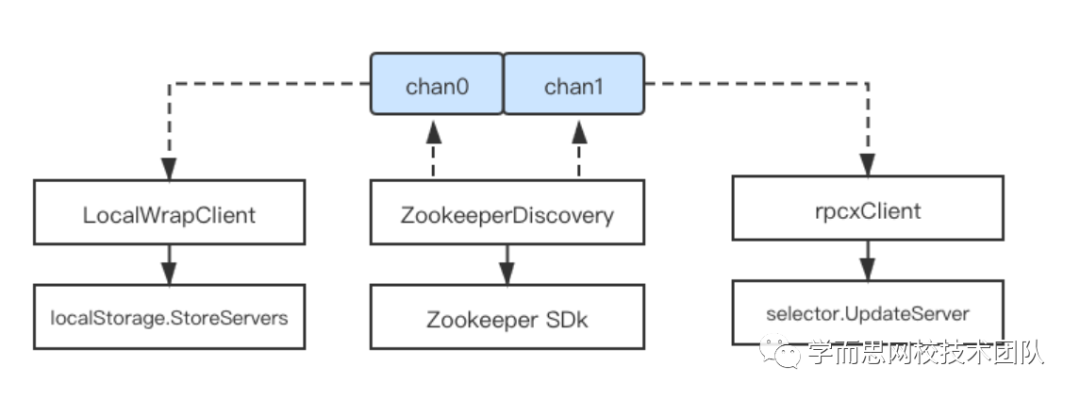
如图所示,ZookeeperDiscovery监听到服务端IP变更时候,将最新的IP列表写入chan,rpcxClient通过chan可获取最新的IP列表,并更新selector(selector提供负载均衡能力)。这个逻辑可以说是非常简单了,没有理由会出现异常。但是事实证明,异常大概率就在这块逻辑。难道是rpcxClient读取chan数据的协程有异常了?看看协程栈帧,也并没有问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
//客户端毕竟不止是只访问一个微服务,所以会存在多个rpcxClient;
//这至少说明ZookeeperDiscovery监听协程与rpcxClient读chan协程数目是一致的。
go tool pprof http://localhost:17009/debug/pprof/goroutine
(pprof) traces
5 runtime.gopark
runtime.goparkunlock
runtime.chanrecv
runtime.chanrecv2
github.com/smallnest/rpcx/client.(*xClient).watch
-----------+-------------------------------------------------------
5 runtime.gopark
runtime.selectgo
github.com/smallnest/rpcx/client.(*ZookeeperDiscovery).watch
|
只能继续探索。。。
联想到之前还添加了服务发现灾备逻辑(防止zookeeper出现异常或者客户端到zookeeper之间链路异常),在监听到zookeeper数据变化时,还会将该数据写入本地文件。服务启动时,如果zookeeper无法连接,可以从本地文件读取服务端IP列表。这时候的流程应该是如下图所示:
查看文件中的IP列表以及文件更新时间,发现都没有任何问题:
1
2
3
4
5
|
# stat /xxxx
File: /xxxx
Access: 2020-12-24 22:06:16.000000000
Modify: 2020-12-29 23:02:14.000000000
Change: 2020-12-29 23:02:14.000000000
|
这就不可思议了,文件中都是正确的IP列表,rpcxClient却不是?而rpcxClient更新数据的逻辑简单的不能再简单了,基本没有出错的可能性啊。难道是基于chan的数据通信有问题?再研究研究chan相关逻辑。
rpcxClient与LocalWrapClient是通过WatchService方法获取通信的chan。可以看到,这里新建chan,并append到d.chans切片中。那如果两个协程同时WatchService呢?就可能出现并发问题,切片中最终可能只会有一个chan!这就解释了为什么本地文件可以正常更新,rpcxClient始终无法更新。
1
2
3
4
5
6
|
func (d *ZookeeperDiscovery) WatchService() chan []*KVPair {
ch := make(chan []*KVPair, 10)
d.chans = append(d.chans, ch)
return ch
}
|
我们再写个小例子模拟一下这种case,验证并发append问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
package main
import (
"fmt"
"sync"
)
func main() {
ok := true
for i := 0; i < 1000; i ++ {
var arr []int
wg := sync.WaitGroup{}
for j := 0; j < 2; j ++ {
wg.Add(1)
go func() {
defer wg.Done()
arr = append(arr, i)
}()
}
wg.Wait()
if len(arr) < 2 {
fmt.Printf("error:%d \n", i)
ok = false
break
}
}
if ok {
fmt.Println("ok")
}
}
//error:261
|
至此,问题基本明了。解决方案也很简单,去掉服务发现灾备逻辑即可。
总结
初次遇到这问题时候,觉得匪夷所思。基于现状,冷静分析问题产生情况,一个一个去排查或者排除,切记急躁。
抓包验证,二进制协议又不方便分析,只能去研究zookeeper通信协议了。最终还是需要一遍一遍Review代码,寻找蛛丝马迹,不要忽视任何可能产生的异常。
最后,Golang并发问题确实是很容易忽视,却又很容易产生,平时开发还需多注意多思考。